پروتکلی در لایه 2 برای جلوگیری از حلقههای شبکهای و مدیریت مسیرهای انتقال دادهها.





در شبکههای کامپیوتری، دو ابزار مهم برای مسیریابی دادهها وجود دارند که هرکدام نقش حیاتی در عملکرد شبکه ایفا میکنند: Routing Table و Topological Database. این دو ابزار، اگرچه به نظر شبیه به هم میآیند، اما کاربردهای متفاوتی دارند و بهطور خاص در پروتکلهای مختلف مسیریابی مورد استفاده قرار میگیرند. در این مقاله، به مقایسه "Routing Table" و "Topological Database"، تفاوتها و کاربردهای هر کدام، و نحوه تعامل آنها در پروتکلهای مسیریابی Link-State و Distance-Vector خواهیم پرداخت.
Routing Table یا جدول مسیریابی، یک ساختار داده است که در آن روترها اطلاعات مربوط به مسیرهای مختلف را ذخیره میکنند. این جدول به روترها این امکان را میدهد که بستههای داده را به مقصد نهایی هدایت کنند. هر ورودی در جدول مسیریابی شامل مقصد، آدرس روتر بعدی (Next Hop)، و هزینه یا متریک مسیر است.
در پروتکلهای مسیریابی Distance-Vector (مانند RIP)، جدول مسیریابی معمولاً توسط پروتکلهایی که بهطور مداوم اطلاعات را از سایر روترها دریافت میکنند بهروز میشود. در مقابل، در پروتکلهای Link-State (مانند OSPF)، جدول مسیریابی معمولاً بهطور خودکار و با استفاده از اطلاعات وضعیت لینک بهروزرسانی میشود.
Topological Database، یا پایگاه داده توپولوژی، یک ساختار داده است که در پروتکلهای مسیریابی Link-State برای ذخیرهسازی اطلاعات وضعیت لینکها (Link State) استفاده میشود. این پایگاه داده اطلاعات دقیقی از توپولوژی شبکه، شامل وضعیت لینکها، هزینهها، و ویژگیهای دیگر لینکها را نگهداری میکند.
در پروتکلهای Link-State مانند OSPF، هر روتر یک نسخه از Topological Database خود را نگه میدارد که بهطور خودکار و دورهای بهروزرسانی میشود. این پایگاه داده به پروتکلهای Link-State این امکان را میدهد که انتخابهای مسیریابی دقیقتر و بهروزتری انجام دهند، زیرا روترها اطلاعات کاملتری از وضعیت شبکه دارند.
در حالی که هم "Routing Table" و هم "Topological Database" برای مسیریابی دادهها در شبکهها استفاده میشوند، تفاوتهای اساسی بین این دو وجود دارد. برخی از تفاوتهای اصلی به شرح زیر است:
اگرچه Routing Table و Topological Database در ابتدا بهنظر دو ساختار داده مجزا میآیند، اما در پروتکلهای مسیریابی Link-State مانند OSPF، این دو با هم تعامل دارند. در این پروتکلها، اطلاعات توپولوژی شبکه ابتدا در Topological Database ذخیره میشود، و پس از آن این اطلاعات برای محاسبه بهترین مسیر و بهروزرسانی جدول مسیریابی استفاده میشود.
برای مثال، در پروتکل OSPF، هر روتر اطلاعات وضعیت لینکهای خود را در قالب LSA ارسال میکند و این اطلاعات در Topological Database ذخیره میشود. پس از بهروزرسانی پایگاه داده توپولوژی، روترها از الگوریتمهایی مانند Dijkstra برای محاسبه کوتاهترین مسیر استفاده میکنند. در نهایت، اطلاعات حاصل از این محاسبات در Routing Table ذخیره میشود و برای هدایت بستهها در شبکه استفاده میشود.
Routing Table مزایای زیادی دارد که از جمله آنها میتوان به موارد زیر اشاره کرد:
Topological Database نیز مزایای خاص خود را دارد که بهویژه در شبکههای بزرگ و پیچیده اهمیت دارد. برخی از مزایای آن عبارتند از:
Routing Table و Topological Database دو ابزار حیاتی در مسیریابی شبکههای کامپیوتری هستند که هرکدام نقشهای متفاوتی در فرآیند مسیریابی ایفا میکنند. در حالی که Routing Table برای مسیریابی سریع و مؤثر بستهها از یک روتر به روتر دیگر استفاده میشود، Topological Database اطلاعات دقیقتری از وضعیت لینکها و توپولوژی شبکه برای مسیریابی بهینه فراهم میکند. این دو ابزار در پروتکلهای مسیریابی Link-State مانند OSPF با یکدیگر همکاری میکنند تا شبکههای پیچیده را بهطور مؤثر مدیریت کنند. برای درک بهتر نحوه تعامل این دو ابزار و بهینهسازی عملکرد شبکه، میتوانید به سایت saeidsafaei.ir مراجعه کنید.
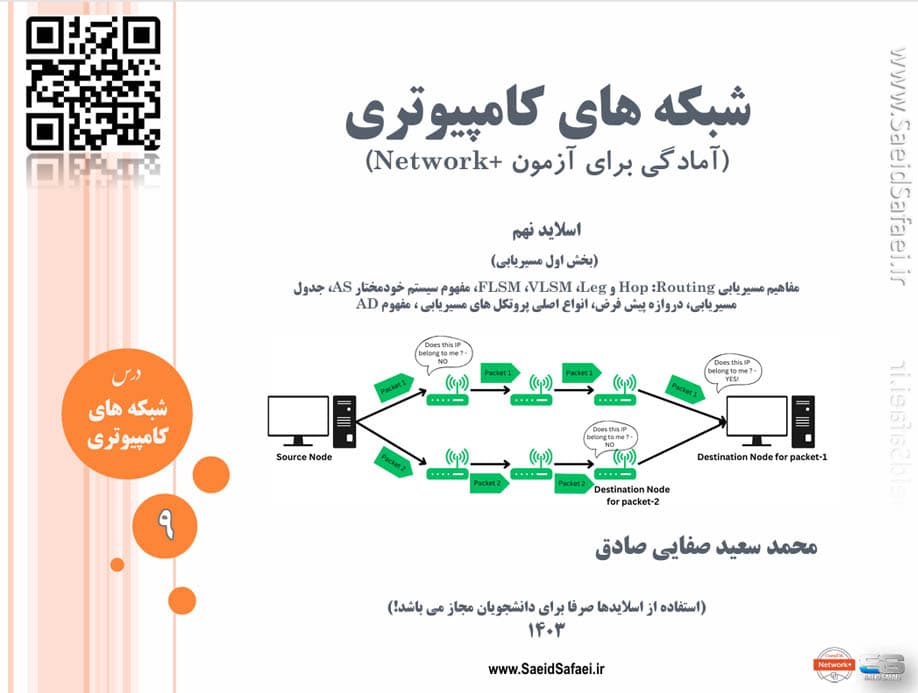
در این جلسه (بخش اول مسیریابی)، مفاهیم پایهای مسیریابی (Routing) مانند Hop، InterVLAN و Leg بررسی میشوند. سپس، تکنیکهای VLSM (Variable Length Subnet Mask) و FLSM (Fixed Length Subnet Mask) توضیح داده میشوند. همچنین، مفهوم سیستم خودمختار (AS) و اهمیت آن در مسیریابی، ساختار جدول مسیریابی و نقش دروازه پیشفرض بررسی خواهد شد. در نهایت، انواع کلاسهای پروتکلهای مسیریابی معرفی و ویژگیهای آنها مورد بحث قرار میگیرد. هدف این جلسه، درک اصول مسیریابی و نحوه مدیریت مسیرها در شبکههای پیچیده است.
پروتکلی در لایه 2 برای جلوگیری از حلقههای شبکهای و مدیریت مسیرهای انتقال دادهها.
کد منبع کدهایی است که به زبان برنامهنویسی توسط توسعهدهندگان نوشته میشود. این کدها پس از تبدیل توسط کامپایلر به کد ماشین، قابل اجرا بر روی پردازندهها خواهند بود.
دستور شرطی به دستوری اطلاق میشود که تصمیمگیریهایی را بر اساس شرایط خاص انجام میدهد، به طور معمول با استفاده از دستورات if, else و switch.
عملیاتهای شیفت که در آنها موقعیت بیتها در دادهها به سمت چپ یا راست حرکت میکنند.
پایگاههای داده گراف به پایگاههای دادهای اطلاق میشود که برای ذخیره و مدیریت اطلاعات در قالب گرافها طراحی شدهاند.
کشف دادههای افزوده به فرآیند تجزیه و تحلیل و استخراج الگوهای جدید از دادههای موجود به کمک هوش مصنوعی گفته میشود.
شیء در برنامهنویسی شیگرا یک نمونه از یک کلاس است که دارای ویژگیها و رفتارهای خاص خود میباشد.
دروازه منطقی OR که زمانی خروجی 1 میدهد که حداقل یکی از ورودیها 1 باشد.
بلاکچین برای اینترنت اشیاء به استفاده از بلاکچین برای اتصال دستگاههای IoT و مدیریت دادهها بهصورت امن و شفاف اشاره دارد.
نوع دادهای است که برای ذخیرهسازی اعداد اعشاری و محاسبات دقیقتری استفاده میشود.
یادگیری ماشین پیشرفته به توسعه و استفاده از الگوریتمها و مدلهای پیچیده برای پردازش دادههای پیچیده و بهبود پیشبینیها اطلاق میشود.
بازگشتی زمانی است که یک تابع یا روش، خود را فراخوانی میکند تا زمانی که شرط خاصی به حقیقت بپیوندد.
حافظههای دینامیک (DRAM) که نیاز به رفرش مداوم دارند، برای حافظههای اصلی به کار میروند. این نوع حافظهها ظرفیت بیشتری نسبت به SRAM دارند.
روش دسترسی به رسانه که در آن یک توکن بهصورت مداوم در شبکه میان دستگاهها جابهجا میشود و تنها دستگاهی که توکن را در اختیار دارد میتواند داده ارسال کند.
یادگیری ماشین خصمانه به استفاده از الگوریتمهایی گفته میشود که مدلهای یادگیری ماشین را از حملات خصمانه برای اختلال در تصمیمگیریهای آنها محافظت میکنند.
حذف به معنای از بین بردن دادهها از ساختارهای دادهای مانند آرایهها یا لیستها است.
محاسبات الهام گرفته از مغز انسان به استفاده از اصول و فرآیندهای مغز برای طراحی سیستمهای محاسباتی جدید اطلاق میشود.
مکانیزمهای اجماع بلاکچین به روشهای مختلفی اطلاق میشود که برای تأیید و تأمین یکپارچگی تراکنشها در شبکههای بلاکچین استفاده میشود.
یونیکد سیستم کدگذاری است که از آن برای نمایش حروف و نمادهای مختلف زبانها در یک سیستم استفاده میشود.
پهپادهای خودمختار به وسایل نقلیه هوایی بدون سرنشین اطلاق میشود که قادر به انجام وظایف خودکار مانند نقشهبرداری و نظارت هستند.
سیستمهایی هستند که قادرند دادهها را پردازش کرده و بر اساس آنها تصمیمگیری نمایند، به گونهای که شبیه به تفکر انسان عمل میکنند.
یک گیگابایت معادل ۱۰^۹ بایت یا 1,073,741,824 بایت است و معمولاً برای اندازهگیری ظرفیت ذخیرهسازی استفاده میشود.
دستیارهای مجازی نرمافزارهایی هستند که از هوش مصنوعی برای شبیهسازی مکالمات انسانی استفاده میکنند تا به کاربران کمک کنند.
عملگر در برنامهنویسی به نمادهایی اطلاق میشود که عملیاتهای مختلفی مانند جمع، تفریق، ضرب و مقایسه را روی دادهها انجام میدهند.
شیوهای برای سازماندهی و ذخیرهسازی دادهها به گونهای که دسترسی به آنها سریعتر و مؤثرتر باشد. انواع مختلفی از ساختار داده مانند آرایهها، لیستهای پیوندی و درختها وجود دارد که هر یک برای مسائل خاصی مناسب هستند.
حلقه do while مشابه با حلقه while است، با این تفاوت که ابتدا دستور اجرا میشود و سپس شرط بررسی میشود.
تحلیلهای پیشرفته به استفاده از دادههای پیچیده و الگوریتمهای پیچیده برای استخراج بینشهای کاربردی اطلاق میشود.
اتوماسیون هوشمند به استفاده از فناوریهای AI برای خودکارسازی فرآیندها و انجام کارهای پیچیده اشاره دارد.
لیست پیوندی دوطرفه یک نوع خاص از لیست پیوندی است که هر عنصر در آن به دو عنصر قبلی و بعدی خود اشاره دارد.
حافظههای استاتیک (SRAM) از نوعی حافظه هستند که دادهها را بدون نیاز به رفرش نگه میدارند. این حافظه معمولاً در کش استفاده میشود.
مدل ارتباطی که در آن دو دستگاه بهطور مستقیم به یکدیگر متصل میشوند.
استاندارد شبکههای بیسیم شخصی که به طور خاص برای ارتباطات بلوتوثی استفاده میشود.
برنامهنویسی شیگرا روشی است که بر اساس آن دادهها و توابع به صورت واحدهای شیء سازماندهی میشوند. این روش به طراحی نرمافزارهای مقیاسپذیر و قابل نگهداری کمک میکند.
نشانی عددی که به هر دستگاه متصل به شبکه اختصاص داده میشود تا آن دستگاه در شبکه شناسایی شود.
عملگرهایی هستند که برای انجام عملیات منطقی مانند AND, OR, NOT و XOR بر روی دادهها به کار میروند.
